使用 Redis 处理 Rails Model 缓存
Model 层的缓存常常都会被忽略,甚至是经验丰富的码农。当你对视图层做缓存时,你不需要进行底层缓存,这是一个非常常见的误解。虽然在 Rails 里大部分的瓶颈在于视图层,但是总有个别情况不是这样的。
底层缓存是非常灵活的,可以工作于任何一个应用程序。在本教程中,我将演示如何使用 Redis 来缓存你的 model 层。
缓存是如何工作的?
过去,访问磁盘的成本已经非常高了。而且从磁盘访问数据经常会对性能产生不利的影响。为了解决这个问题,我们可以在应用程序和数据库服务器之间加上缓存层。
缓存层在初始化时是没有任何数据的。当它接收到数据请求时,它会调用数据库并将结果存储在内存中(缓存)。所有后续的请求将从缓存层直接读取数据,所以可以避免不重复往返的访问数据库服务器,从而提高性能。
为什么使用 Redis?
Redis 是一个基于内存、Key-Value 存储系统。它的速度极快,几乎是瞬间完成数据检索。Redis 支持先进的数据结构,如链表,哈希表,集合,并能持续保存到磁盘。
虽然大多数码农更喜欢使用 Memcache 和 Dalli 去处理他们的缓存化的需求,但我发现 Redis 非常容易的安装和方便管理。另外,如果你使用的是 resque 或 Sidekiq 管理你的队列,你很可能已经安装了 Redis 了。对于那些有兴趣了解何时使用 Redis 的朋友们,可以到这个 讨论 里了解更多相关信息。
前提
我假设你的项目正在使用 Rails,文章中的例子是使用 Rails 4.2.rc1,使用 haml 渲染视图和 MongoDB 作为数据库,但是本教程的片段应该适用于任何版本的 Rails。
在开始之前,你需要安装和运行 Redis。进入你的应用程序目录,并执行以下命令:
1 | $ wget http://download.redis.io/releases/redis-2.8.18.tar.gz |
这个命令将需要一段时间才能完成。一旦完成了,就可以开启 Redis 服务了:
1 | $ cd redis-2.8.18/src |
使用 gem “rack-mini-profiler” 可以测量性能提升,这个 gem 可以帮助我们正确的体现出性能的改善。
# 开始
例如,让我们构建一个虚拟的在线故事书阅读书店。这个书店有各种各样的书籍和语言。首先,让我们创建模型:
1 | # app/models/category.rb |
这里包括了一个 seed 数据文件。只要复制粘贴到你的 seeds.rb 和运行 rake seed 任务,数据就会加载到我们的数据库中。
1 | rake db:seed |
现在,让我们创建一个简单的 Category 列表页面,该页面显示了所有 Categories 的描述和标记信息。
1 | # app/controllers/category_controller.rb |
当你打开浏览器并将其地址指向 /category 时,你会发现 mini-profiler benchmarking 显示在后端执行每一个动作的时间。这些正确的数据是告诉你,你的应用程序哪部分比较缓慢和应该如何优化它们。本页面执行了两条 SQL 语句并且使用了 5ms 的时间完成查询。
虽然起初看起来好像 5ms 是无关紧要的,特别是在需要更多时间去渲染视图时,但在一个生产级别的应用程序中有多次数据库查询时,它们可以明显的降低软件的性能。
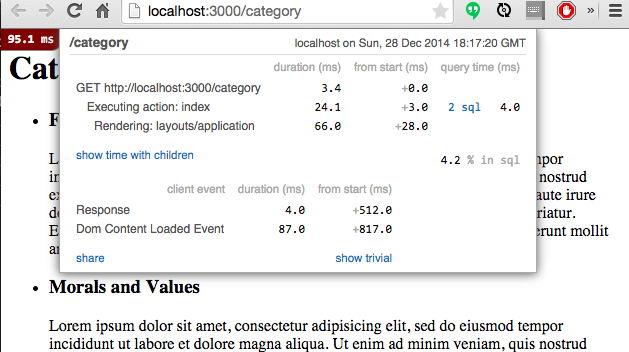
由于元数据模型是不太可能发生改变的,这样就可以避免不必要的数据库切换。这一点也是底层缓存的用武之地。
# 安装 Redis
使用 Redis 基于 Ruby 的客户端来帮助我们非常方便的链接 Redis 实例:
1 | gem 'redis' |
一但安装好这些 gem 后,就可以配置 Rails 使用 Redis 来作为缓存存储:
1 | # config/application.rb |
使用 redis-namespace gem 可以让我们创建一个更好的 Redis 命名空间:
1 | # config/initializers/redis.rb |
现在所有的 Redis 功能都可以通过 $redis 进行全局使用了。以下的一个例子是体现如何访问在 redis 服务器上的值(运行于 Rails console):
1 | $redis.set("test_key", "Hello World!") |
这个命令创建了一个 key:“test_key” 和 value:“Hello World” 保存在 Redis 中。要取这个值,只做:
1 | $redis.get("test_key") |
现在,我们有了基础知识,让我们开始重写我们的 helper 方法:
1 | # app/helpers/category_helper.rb |
在第一次执行这部分代码时,内存 / 缓存中是没有任何东西的。所以我们请求 Rails 把数据从数据库推送到 Redis 中。注意到 to_json 的调用了吗?当要写对象进 Redis,我们多种方式。一种选择是遍历对象中的每个属性,然后将它们保存为一个哈希函数,但是这种方式较为缓慢。最简单的方法是将它们保存为一个 JSON 编码的字符串。解码,只需使用 JSON.load 。
然而,这有一个意想不到的副作用。当我们正在检索这个值时,一个简易的对象符号不工作。我们需要更新视图并使用哈希语法来显示该类型:
1 | # app/views/category/index.html.haml |
重新启动浏览器,并看看性能是否有所不同。首次访问,我们仍然访问数据库,但随后的重新加载将不在访问数据库了。以后所有的请求都将直接从缓存中读取。这个简单的变化非常有效。
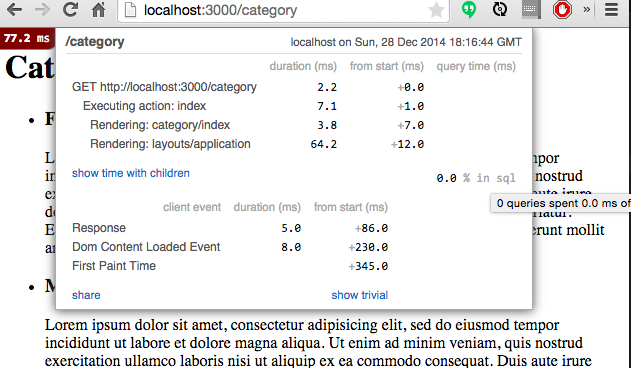
# 管理缓存
我刚发现一个关于 categories 的错误。让我们先解决它:
1 | $ rails c |
重新加载并查看该更新是否显示在视图中:

很遗憾,我们的视图上并没有体现出这个变化。因为我们并没有访问数据库,所有的数据都直接从缓存中读取。唉,现在的缓存已经过期,直到 Redis 重启前被更新都数据都无法使用。这个对于大多数应用程序来说真是一个破坏者啊。我们偶尔可以使用缓存到期来解决这个问题:
1 | # app/helpers/category_helper.rb |
缓存将会在每 3 个小时就失效。虽然这对大多数情况下工作,缓存中的数据将滞后于现在数据库。这种工作方式很可能不抬适合你。如果你喜欢保持缓存的更新,我们可以使用 after_save 这个回调:
1 | # app/models/category.rb |
每次模型的更新,我们都将通知 Rails 去清除缓存。这样可以确保缓存是最新的。Yay!
你应该使用类似 cache_observers 在生产环境中,为了保持简洁,我们在这里坚持使用 after_save。如果你不知道哪种方法最适合你,这里的讨论可能会对你有所启发。
# 结论
底层缓存是非常简单的,如果使用得当,它是非常有价值的。它可以在你花费最小的努力下瞬间提高你的系统的性能。在这篇文章中所有的代码片断可以在 GitHub 上找到。